
(Part 1) How to train your dragon inverted double pendulum
If you haven’t been living under a rock these past few years, you’ve probably noticed the incredible evolution of humanoid robotics. We’ve seen robot dogs learn how to walk, humanoid robots learn to walk and do dishes, and who knows, maybe robot birds will learn to fly in the future?
After working with “traditional” navigation robotics (SLAM, navigation, etc.) on my Just1 project , I wanted to try something new with control. Reinforcement learning is one of those cool techniques that can teach robots how to move.
Before learning how to walk, we need to learn how to crawl. So, how about learning how to balance an inverted double pendulum?
First of all, what is Isaac Sim? And Isaac Lab?
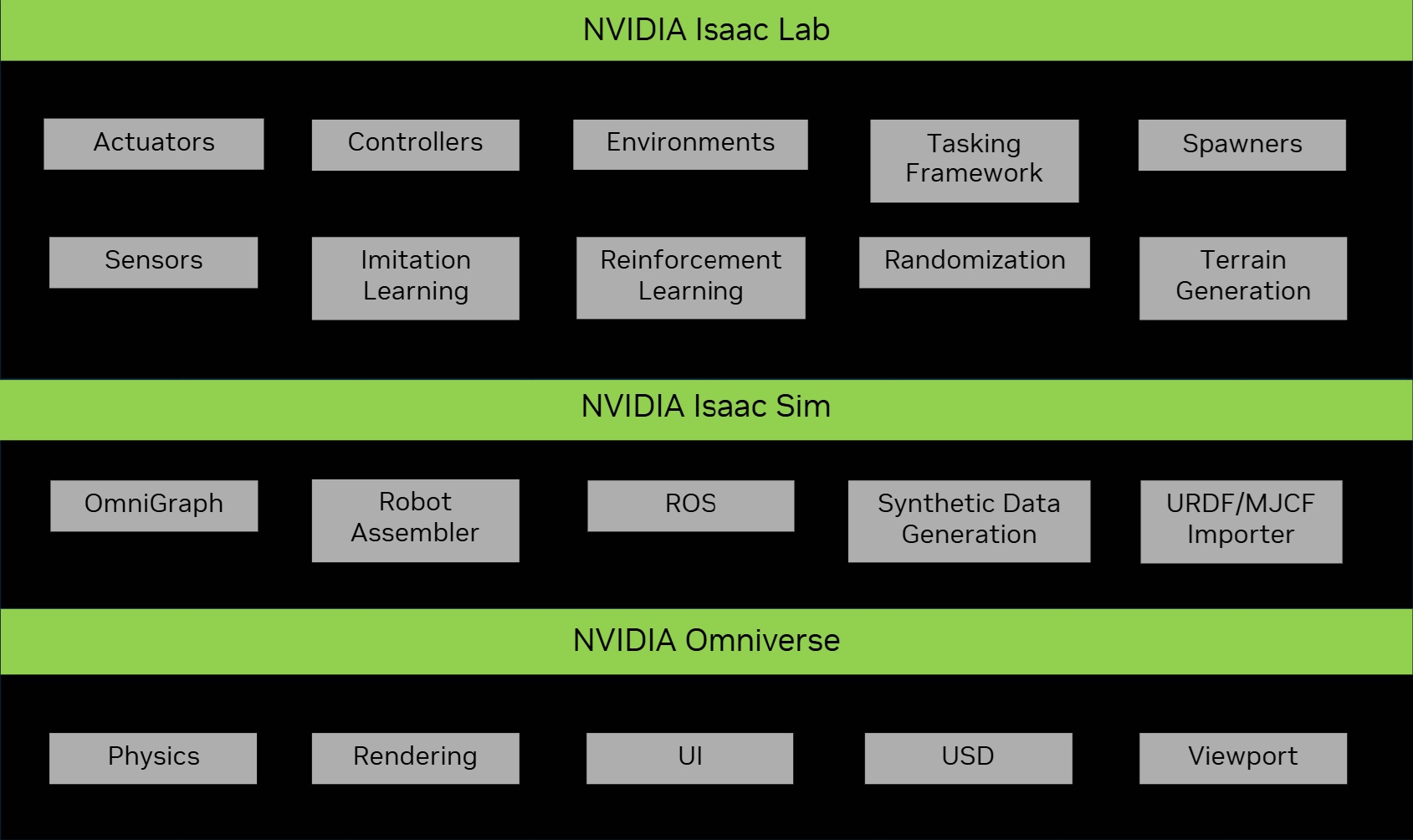
Okay, so Nvidia Isaac Sim and Isaac Lab are both part of this ecosystem called “Omniverse”, which honestly can be pretty confusing at first.
 Source: Isaac Lab Documentation
Source: Isaac Lab Documentation
Think of Omniverse as the “operating system” for 3D simulation. Isaac Sim sits on top of that and focuses on robotics simulation. It works with ROS, URDF, and all those other robotics standards. Then Isaac Lab sits on top of Isaac Sim and lets you do reinforcement learning with your robots.
Beyond Omniverse, Nvidia also has:
- Nvidia Cosmos: For generating realistic synthetic 3D worlds and videos
- Nvidia Gr00t: A general purpose foundation model to control humanoid robots
- Isaac ROS: A collection of ROS packages built to be accelerated on Nvidia GPUs
In our case, we’ll build our robot within Isaac Sim and train it using reinforcement learning with Isaac Lab.
Let’s build our pendulum
I designed the double pendulum in Onshape. I have more experience with SolidWorks, but Onshape was easy to pick up. Everything is in the cloud, it has a built-in versioning system, and it’s straightforward to export to URDF format.
What is URDF? URDF (Unified Robot Description Format) is basically an XML file that describes your robot. Things like its parts, joints, what it looks like, and how it collides with stuff. It’s the standard way to describe robots in ROS and most simulation tools, including Isaac Sim. We need it because Isaac Sim reads these files to figure out how to load and simulate our robot.
As if balancing an inverted double pendulum wasn’t hard enough, I decided to add a small sign to the second arm to throw it off balance even more.
The double pendulum consists of:
- A rail (fixed base)
- A cart that slides along the rail (controlled by the agent)
- A first arm attached to the cart
- A second arm attached to the first arm
- A small sign attached to the second arm
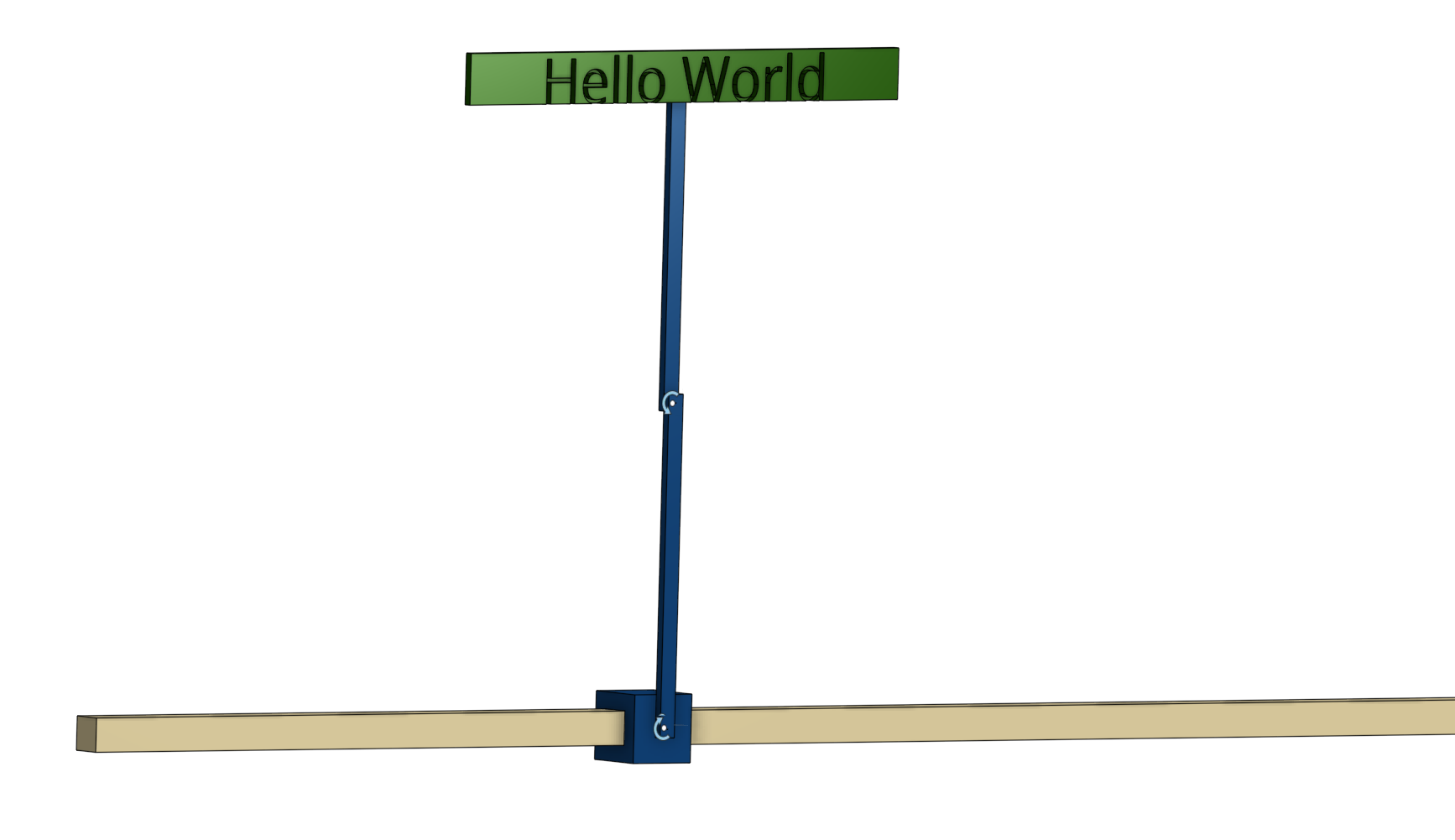
The tricky part? The agent can only control the horizontal force on the cart. It has to figure out how to keep both pendulum arms standing upright.
Manually balancing our pendulum
After importing the URDF into Isaac Sim, I made sure everything worked. I spent a while tweaking the joint physics, things like stiffness and damping for the cart sliding on the rail, to make it behave as realistically as possible. This matters a lot because if your simulation physics are realistic, your robot will work better when you try it on real hardware. That’s a whole topic on its own, so I’ll save the details for another time.
I tried to balance the pendulum manually using the cart controls. Let me tell you, it’s incredibly hard! The double pendulum is a chaotic system, and even small errors compound quickly. But we live in 2025 now, and we have AI to do the tedious work for us, even balance our pendulums.

It’s training time
I created a new project in Isaac Lab using their template system. Everything, loading the URDF, setting up joints, configuring physics, it’s all done through code.
You can find the code on Github here .
Now here’s the key part of reinforcement learning: we need to define rewards. The model trains a bunch of instances at the same time (4,096 in my case!) and tries to get the highest total reward.
For our inverted double pendulum, we want both arms to stay straight up. Here’s the basic reward setup:
-
Upright position reward: We penalize the agent when the arms tilt away from vertical. The more they tilt, the bigger the penalty. This is the main goal.
-
Smooth motion rewards: We also penalize high speeds, both how fast the arms swing and how fast the cart moves. This stops the robot from being all jerky and wobbly, and makes it move smoothly instead.
Each reward has a weight that says how important it is. The agent gets these rewards every step of the simulation. The neural network figures out how to balance all these competing goals by trying different things across thousands of parallel simulations.

With this reward setup, we’re ready to train! I used the PPO (Proximal Policy Optimization) algorithm with the skrl library, which works really well for this kind of continuous control task.
Finding the right weights for these rewards was one of the biggest headaches. If the upright position reward is too weak, the agent just never learns to balance. If the smooth motion penalties are too strong, the agent gets too cautious and can’t make quick corrections when things go wrong. I spent a lot of time tweaking these weights, running training, watching what happened, and adjusting.
There are a few ways to make this easier. One common trick is curriculum learning. Start with simpler goals (like just balancing from an upright position) and slowly add more complex rewards. Another option is to use reward normalization or scaling, which automatically balances the different reward parts. Some people also use automated tools to search for the best hyperparameters. For this project, I did it the manual way, but those techniques can save you a ton of time.
Here is a gif showing our 4,096 instances learning how to balance themselves in parallel.

Under the hood
If you want to understand the magic behind the scenes, check out Part 2: Behind the scenes . I explain how reinforcement learning actually works, what PPO does, and how neural networks learn from rewards.
For now, just know that the agent tries different things, figures out what works, and gets better over millions of simulation steps.
Our trained policy
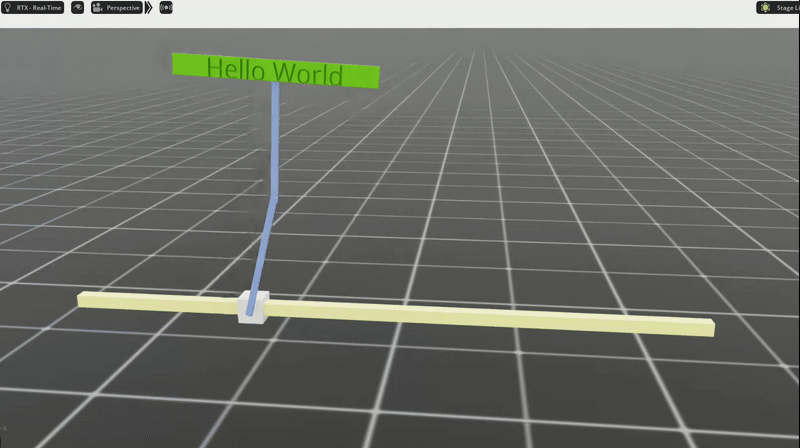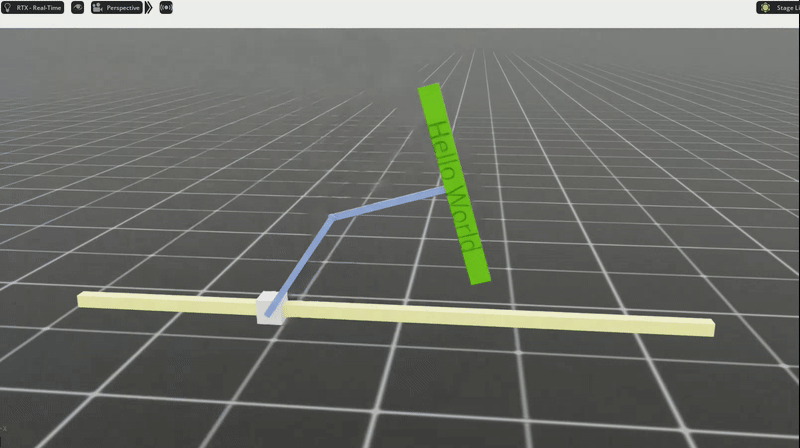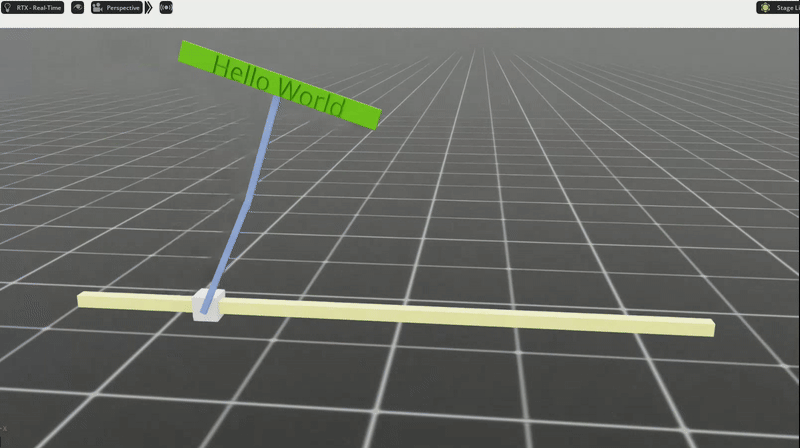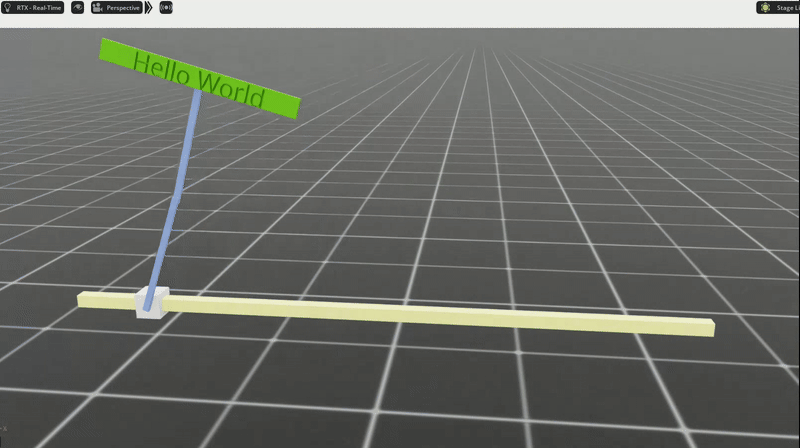
After just 20 minutes of training (on my 4080 Super), we have a policy that “learned” how to swing up the arms and keep them balanced. Check out this gif where I push the robot around to mess it up, and it recovers back to standing upright.
What’s next?
So now we have a trained neural network! It takes in the positions and speeds of both arms, plus the position and speed of the cart, and spits out a force to apply to the cart to keep everything balanced.
The neural network itself is pretty simple. It’s just a feedforward network. You give it the current state, it goes through a few hidden layers, and out comes the force. The “magic” is all in the weights, which were learned through millions of trials in simulation.
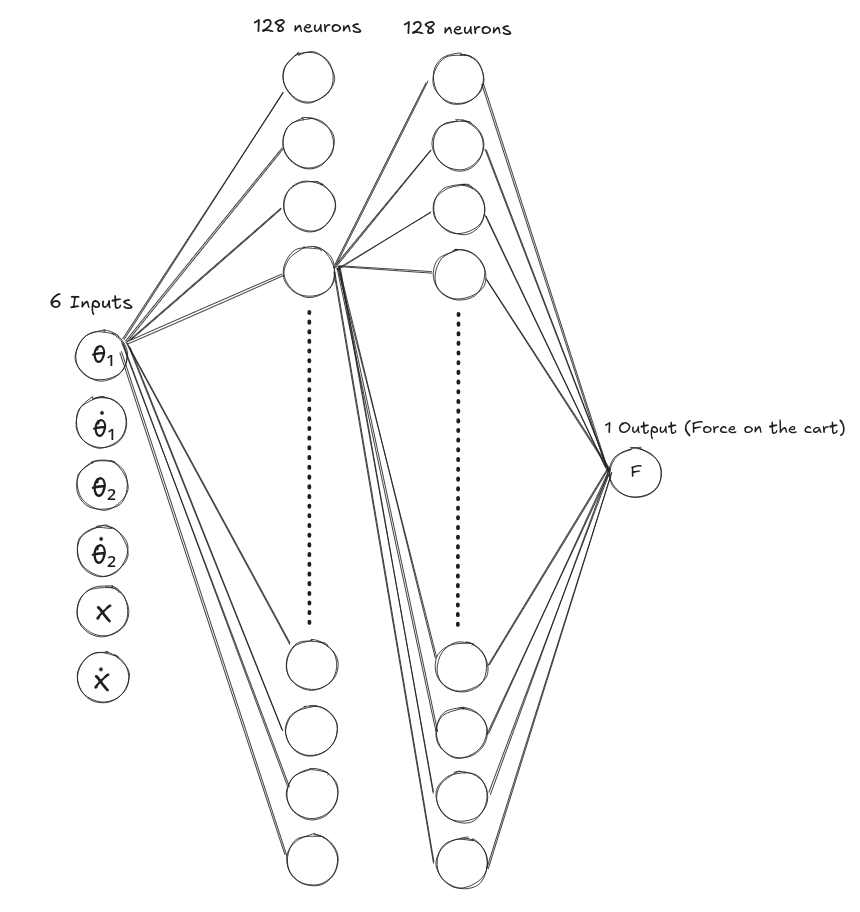 Note: All neurons in each layer are interconnected to neurons in adjacent layers.
Note: All neurons in each layer are interconnected to neurons in adjacent layers.
The next big step would be to take this neural network and put it on a real robot with real motors. This is called “sim to real” transfer, and that’s where things get really interesting. Having realistic physics in your simulation becomes super important here. You need to make sure your joint stiffness, controller force, and frequency are actually possible in the real world.
For example, in our simulation, we set up a force of up to 100N and a 60Hz control frequency. This means our real-time controller needs to:
- Read sensors
- Run the neural network (do inference)
- Send commands to the motor
All in just 16.67ms (one control cycle).
How to walk from there?
We’ve trained a system with 3 degrees of freedom (the cart position and two arm angles). A humanoid robot has something like 20 to 30 degrees of freedom just for walking. The idea is the same. Define rewards, train in simulation, and transfer to reality. But the complexity and computing power needed goes way up.